Predicting BGG ratings from boardgame descriptions
I attempt to fine-tune a transformer-based model on boardgame descriptions from BoardGameGeek.com to predict games' average ratings.
The model performs better than random guessing, with an accuracy of 0.35 on the test set (compared to a baseline of 0.2 for random guessing).
However, the model performs worse than an XGBoost model trained on boardgame metadata (player count, playing time, etc.) and decision tree model using description length only.
Introduction
BoardGameGeek.com (BGG) is boardgame website that provides a database of boardgames and allows users to post ratings and reviews. For each boardgame, BGG provides an average of user ratings. BGG also provides a textual description for each game, which may be provided by the game's publisher or designer, or may be contributed by users of the site.
In this note, I describe my use of a transformer-based model to predict the average ratings of boardgames on BGG using the textual descriptions of the games.
Data
I use data from BoardGameGeek.com, which I downloaded from a Kaggle page. I also use BoardGameGeek data as used in a Tidy Tuesday project in January 2022. Both datasets were created by accessing the BoardGameGeek.com API. I combine the two datasets because the Tidy Tuesday version contains original description text, while the Kaggle version includes more detailed information on ratings.
After merging the two datasets, we have 21,375 boardgames.
Rating data
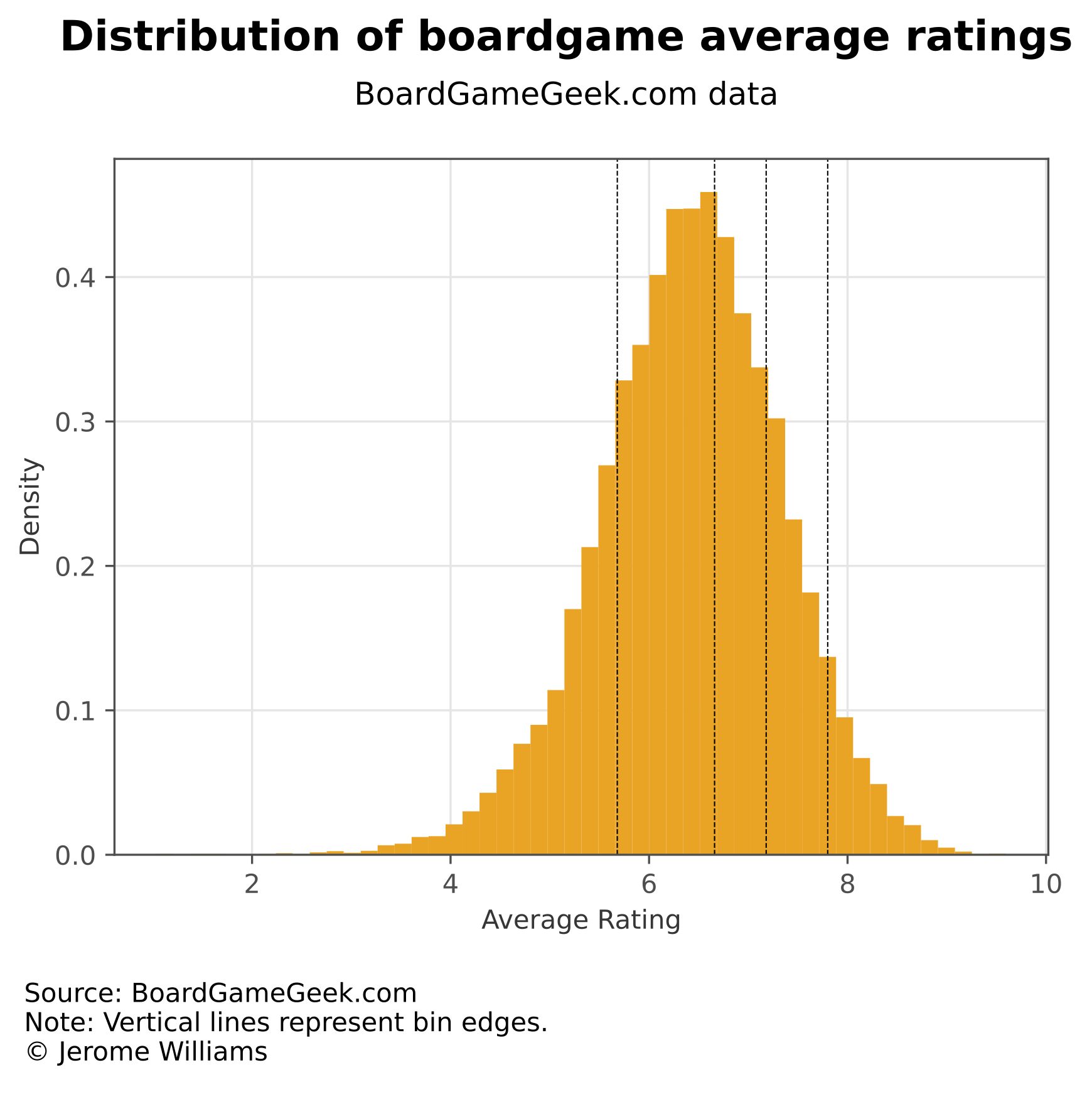
I bin the boardgame ratings into 5 bins of equal size. The rating bins are as follows:
| Rating bin | Range |
|---|---|
| 1 | 1.0-5.68 |
| 2 | 5.68-6.21 |
| 3 | 6.21-6.66 |
| 4 | 6.66-7.18 |
| 5 | 7.18-10.0 |
Figure 1 below plots the distribution of average ratings, as well as the edges of the five equally-sized rating bins.
Description data
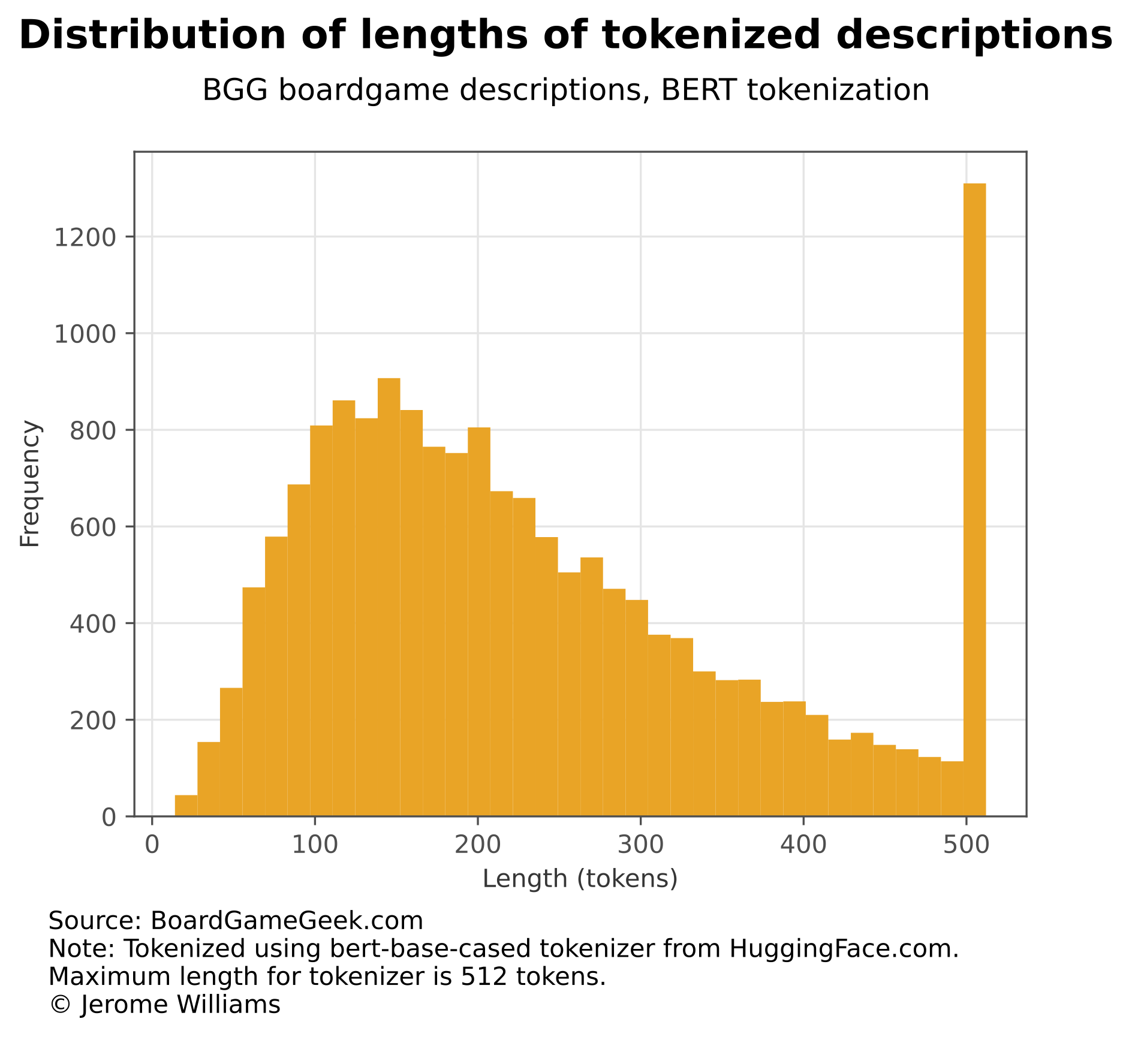
Boardgames descriptions are tokenized using the bert-base-cased tokenizer. The plot below shows the distribution of tokenized description lengths. (Descriptions are truncated at 512 tokens.) Figure 2 below
Model
I fine-tune a transformer-based model on the boardgame descriptions to predict the average ratings of the games. I use the BERT pre-trained model, which is a transformer-based model, trained on a corpus of English texts on masked language modeling and next sentence prediction tasks. I use the bert-base-cased version of BERT, as made available on HuggingFace.com.
Findings
The BERT-based model is relatively successful
The transformer-based model does have some success in predicting the average boardgame rating. Accuracy for the test set is approximately 0.35, while random guessing would result in accuracy of 0.2 (since we have five rating bins).
However, performance is not as good as the characteristics-based model for boardgame ratings we trained previously. The root mean squared error (RMSE) is approximately 2.1 for the transformer-based model, as compared to RMSE of 0.66 from the characteristics-based model for boardgame ratings.
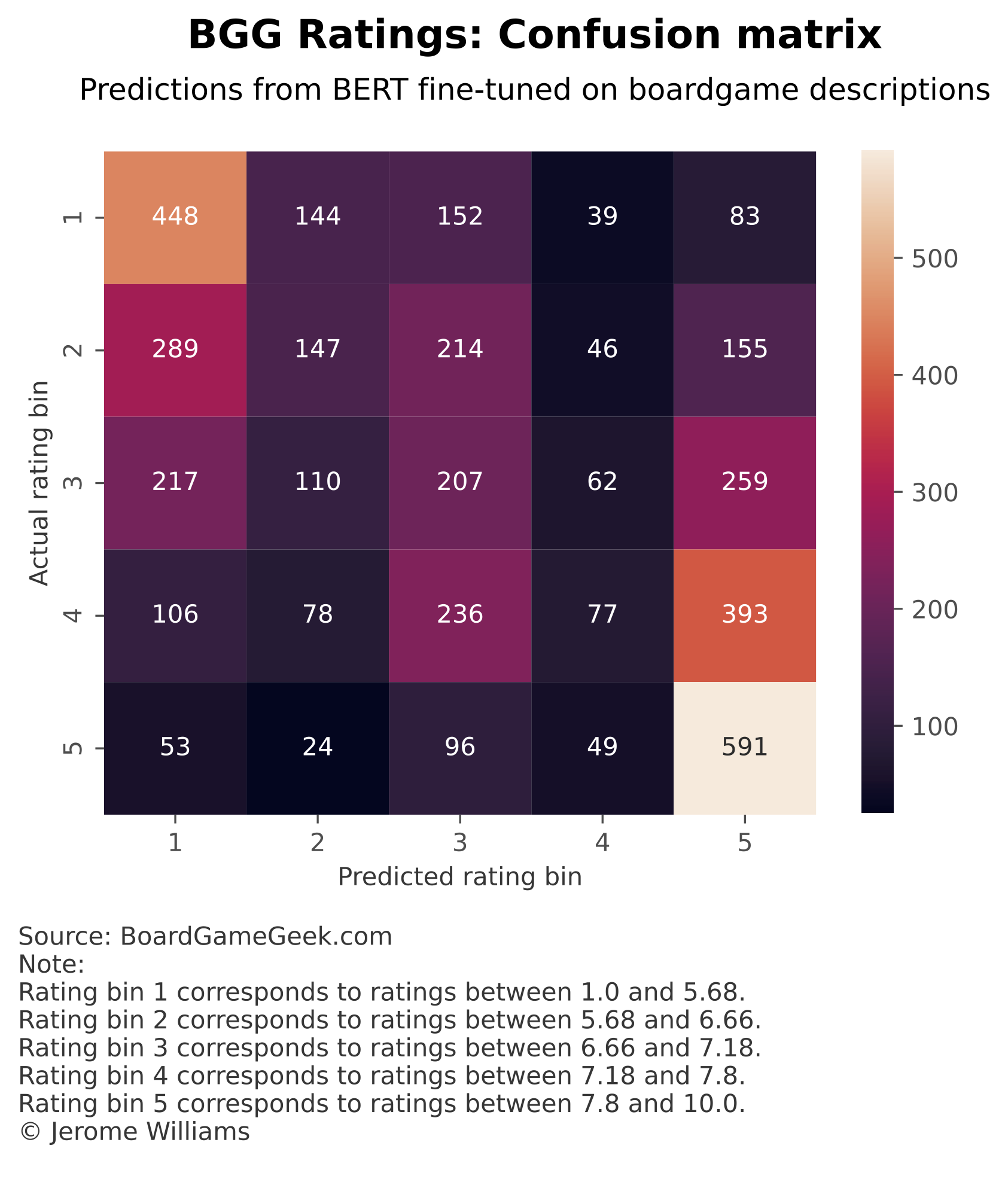
Figure 3 below plots a confusion matrix for the transformer-based model's predictions on the test set. The confusion matrix shows combinations of actual and predicted ratings. As Figure 3 shows, the model does reasonably well at separating observations with very low and very high ratings (rating bins 1 and 5) but does less well for observations in the middle. The models seems especially reluctant to predict rating bins 2 and 4.
Is description length sufficient?
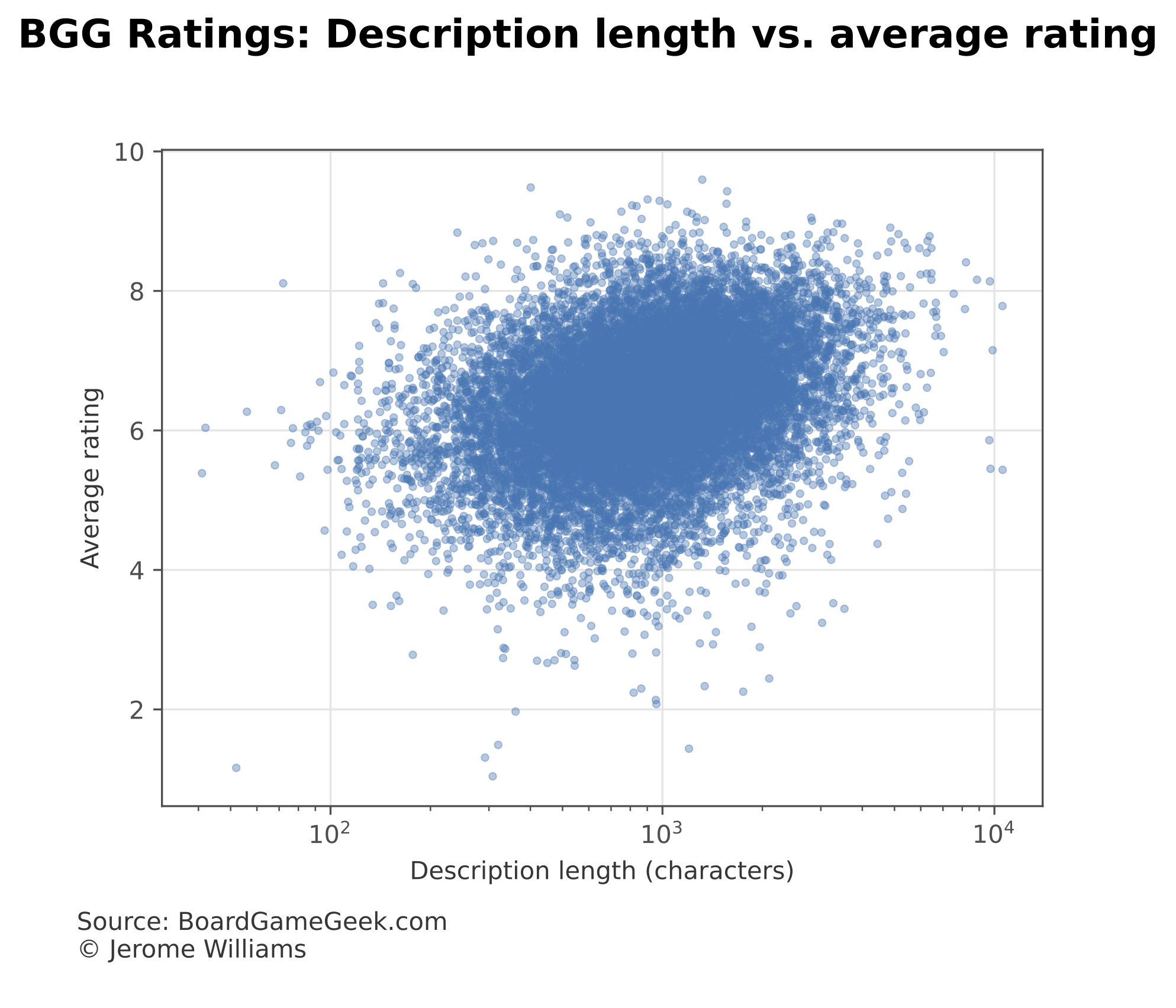
One possible question is whether the transformer-based model is simply using description length to predict ratings. As Figure 4 below shows, there is a relationship between description length and average rating.
I train a simple decision tree model using only the description length as a feature. The description-length-only model achieves RMSE on the test set of 1.8, an improvement on 2.1, the RMSE achieved by the transformer-based model. The confusion matrix for the description-length-only model is shown in Figure 5 below.
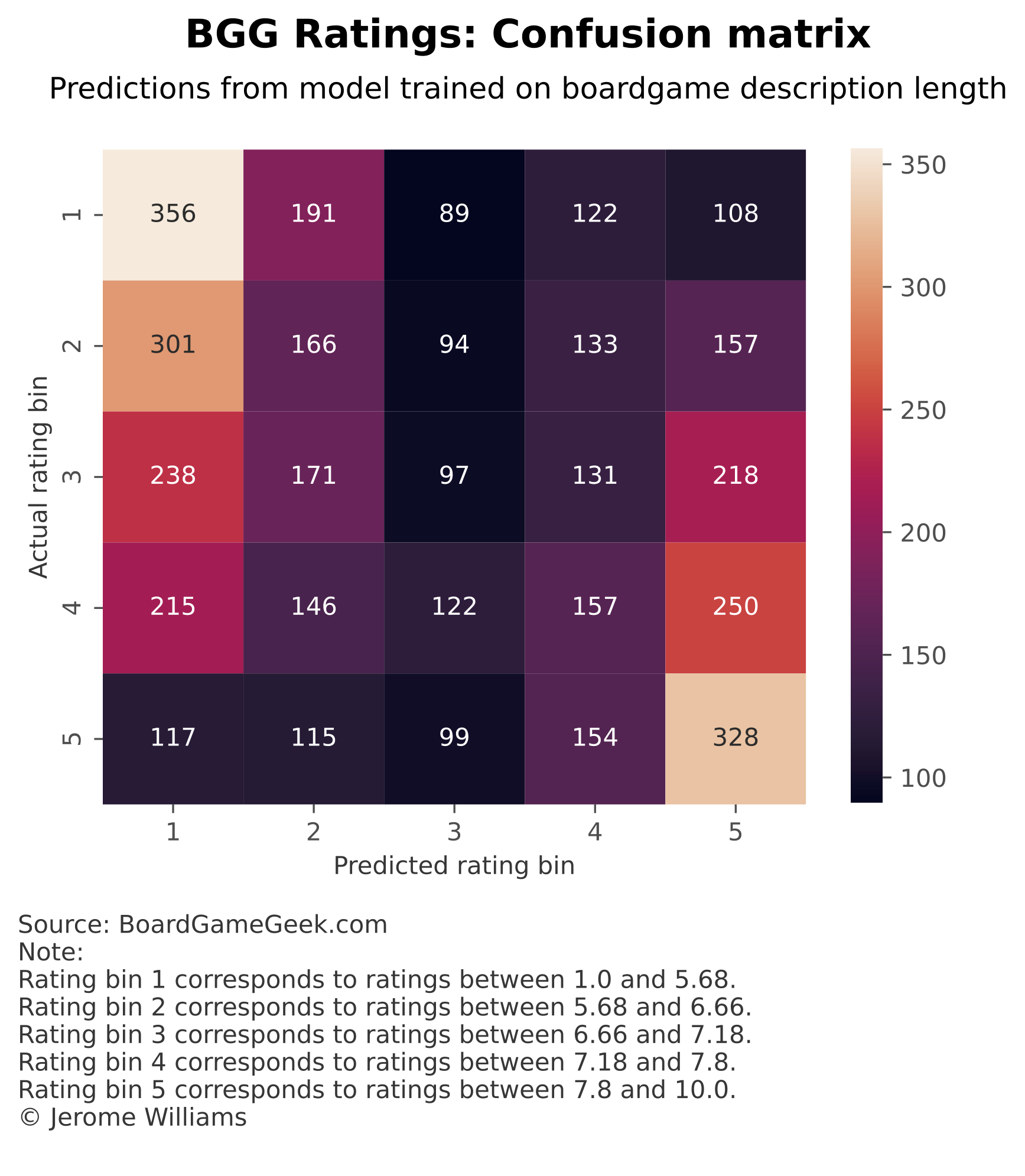
As Figure 5 shows, the description-length-only model, like the transformer-based model, is most accurate for observations in rating bin 1 or 5.
Summary
The table below summarizes the performance of the three models we have trained to predict boardgame ratings.
| Model | RMSE |
|---|---|
| Characteristics-based model (XGBoost) | 0.66 |
| Transformer-based model (BERT) | 2.1 |
| Description-length-only model (Decision tree) | 1.8 |